Introduction
Fruit API is a universal deep reinforcement learning framework, which is designed meticulously to provide a friendly user interface, a fast algorithm prototyping tool, and a multi-purpose library for RL research community. In particular, Fruit API has the following noticeable contributions:
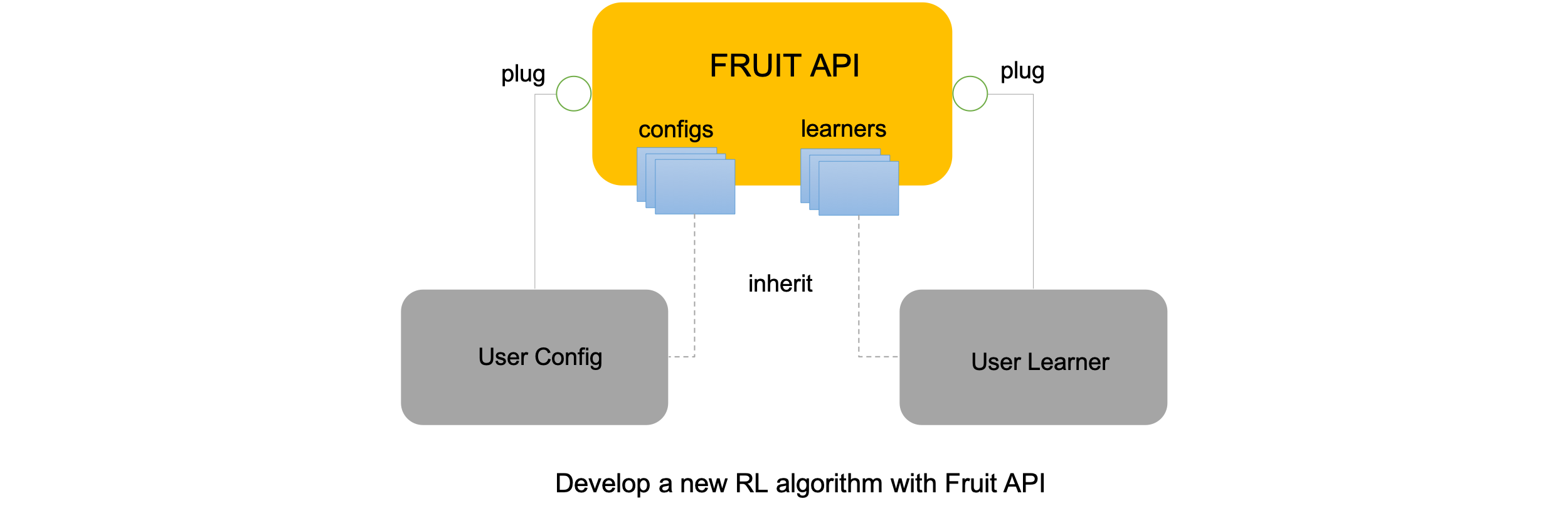
- Friendly API: Fruit API follows a modular design combined with the OOP in Python to provide a solid foundation and an easy-to-use user interface via a simplified API. Based on the design, our ultimate goal is to provide researchers a means to develop reinforcement learning (RL) algorithms with little effort. In particular, it is possible to develop a new RL algorithm under 100 lines of code. What we need to do is to create a
Config, aLearner, and plug them into the framework. We also provides a lot of sampleConfigs andLearners in a hierarchical structure so that users can inherit a suitable one.
- Portability: The framework can work properly in different operating systems including Windows, Linux, and Mac OS.
- Interoperability: We keep in mind that Fruit API should work with any deep learning libraries such as PyTorch, Tensorflow, Keras, etc. Researchers would define the neural network architecture in the config file by using their favourite libraries. Instead of implementing a lot of deep RL algorithms, we provide a flexible way to integrate existing deep RL libraries by introducing plugins. Plugins extract learners from other deep RL libraries and plug into FruitAPI.
- Generality: The framework supports different disciplines in reinforement learning such as multiple objectives, multiple agents, and human-agent interaction.
Features
We also implemented a set of deep RL baselines in different RL disciplines as follows.
- RL baselines.
- Q-Learning
- Monte-Carlo
- Value-based deep RL baselines.
- Deep Q-Network (DQN)
- Double DQN
- Dueling network with DQN
- Prioritized Experience Replay (proportional approach)
- DQN variants (asynchronous/synchronous method)
- Policy-based deep RL baselines.
- A3C
- Multi-agent deep RL.
- Multi-agent A3C
- Multi-agent A3C with communication map
- Multi-objective RL/deep RL.
- Q-Learning
- Multi-objective Q-Learning (linear and non-linear method)
- Multi-objective DQN (linear and non-linear method)
- Multi-objective A3C (linear and non-linear method)
- Single-policy/multi-policy method
- Hypervolume
- Human-agent interaction.
- A3C with human strategies
- Divide and conquer strategy with DQN
- Plugins
- TensorForce plugin (still experimenting). By using TensorForce plugin, it is possible to use all deep RL algorithms implemented in TensorForce library via FruitAPI such as: PPO, TRPO, VPG, DDPG/DPG.
- Built-in environments.
- Arcade Learning Environment (Atari 2600)
- OpenAI Gym
- DeepMind Lab
- Carla (self-driving car)
- TensorForce's environments (by using TensorForce plugin)
- OpenAI Retro
- Deepmind Pycolab
- Unreal Engine
- Maze Explorer
- Robotics - OpenSim
- Pygame Learning Environment
- ViZDoom
External environments can be integrated into the framework easily by plugging into FruitEnvironment. Finally, we developed extra environments as a testbed to examine different disciplines in deep RL:
- Grid World (graphical support)
- Puddle World (graphical support)
- Mountain car (multi-objective environment/graphical support)
- Deep sea treasure (multi-objective environment/graphical support)
- Tank battle (multi-agent/multi-objective/human-agent cooperation environment)
- Food collector (multi-objective environment)
- Milk factory (multi-agent/heterogeneous environment)
Video demonstrations can be found here (click on the images):
Credit
Please cite our work in your papers or projects as follows. All contributions to the work are welcome.
Ngoc Duy Nguyen, Thanh Thi Nguyen, Hai Nguyen, and Saeid Nahavandi, "Review, Analyze, and Design a Comprehensive Deep Reinforcement Learning Framework," arXiv:2002.11883 [cs.LG], 2020. Paper Link